
Moving from a relational database, like MySQL, to a NoSQL database, like Couchbase, requires that you change the perspective on your data. In this article, MC Brown explains the differences between structuring data for a MySQL and a Couchbase database. He also discusses how these differences impact your queries.
Author: MC Brown, Couchbase, http://www.couchbase.com/
This article was originally published on http://blog.couchbase.com/how-move-mysql-couchbase-server-20-part-1 and is reproduced here with Couchbase permission.
If you have a database built using MySQL, you might be wondering if, and more importantly how, that database (and your application) can be moved to Couchbase. The biggest stumbling block is not the technical aspects of creating the Couchbase or storing your information (although they are important), instead it’s about looking at your data in a different way, and then knowing how that changes how your application works.
We’re going to start by looking at how you can turn your MySQL database structure into Couchbase Server, and how querying your database in Couchbase Server differs from the methods used in MySQL.
Think about the data structure first
MySQL (and other SQL and table based databases) force you to think about your data in terms of tables. All your data is a table, and when storing complex structures, an individual piece of data may be split across one or more tables. For some applications and datatypes this is a perfectly logical and reasonable way of approaching and storing your data. But for some applications the table structure does not map very well to the data you want to store.
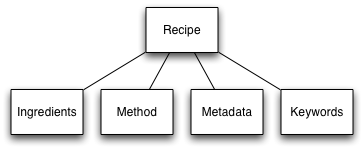
Let’s take a typical example, a recipe database. This is something I know well, since Cheffy.com is built on top of MySQL. The basic table structure is a core table, called recipe, which contains the recipe name, subtitle, description, and servings. Other relevant information about the recipe, such as the list of ingredients, method steps, metadata, and keywords are stored in other tables, linked to the original recipe by a unique recipe ID. You can see this, very basically, in the figure below.

There are some potential benefits to this structure — certain operations for example can be very straightforward and easy. For example, want to find all of the recipes that have the ingredient ‘carrot’? You can perform a query on the ingredients table looking for ‘carrot’, and from that, get a list of matching recipes. By using joins you can get a list of the recipes, their title and other info from the recipe table, by searching on the ingredient table, using the join to connect the recipe ID in the ingredients table to the recipe ID in the recipe title.
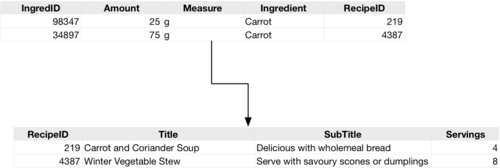
While this kind of search is easy, collecting all of the information about a recipe, for example when you want to display the recipe to the user, can be really complicated. You could do it with a single query, but it can sometimes be easier to do it with multiple queries, one to get the recipe data, one for the ingredients, another for the metadata and so on. Within the application layer, this is done automatically to build up an object, which is then used as the basis for displaying the recipe to the user in a formatted way.
For many users and applications, either a special layer is built to do this, or one of the many object-relational mapping systems to used to map the data from the underlying tabular structure, into the top-level object that the application (and user) is familiar with. Recipes here are one example, but it extends to a wide variety of other applications, including invoicing (invoice, supplier, destination, invoice lines) and blog posts (post content, keywords, creator, comments).
Such table-based solutions are not inherently bad, but for this type of situation, the key information is being stored across multiple tables, and that means keeping the multiple tables in synchronization with each other. For example, what happens when a record is deleted? You have to delete all the other records that might have linked to the original, either manually, or using cascading deletes). Similarly, when it comes to loading the information about a recipe, you end up running 5-10 queries the information together.
Couchbase takes a different approach. Instead of multiple tables in which you can store different pieces of information, within Couchbase you store a single structure (in JavaScript Object Notation JSON) format. The JSON format allows for a complex structure of fields, arrays, objects, and scalar types, that can be combined together into an entire record. That means that you can now represent your old, multiple-table, entity (recipe, blog post), as a single ‘document’.
{
"title" : "Carrot and Coriander Soup"
"servings" : 4,
"subtitle" : "Delicious with wholemeal bread",
"preptime" : 8,
"cooktime" : 12,
"totaltime" : 20,
"ingredients" : [
{
"amount" : 250,
"ingredient" : "Carrots",
"measure" : "g"
},
{
"amount" : 75,
"ingredient" : "Coriander",
"measure" : "g"
},
{
"amount" : 250,
"ingredient" : "Vegetable Stock",
"measure" : "ml"
}
],
"method" : [
"Chop carrots",
"Cook all ingredients in pan",
"Liquidize"
}
],
}
Now everything to do with your recipe is in one place, and we can load the recipe in one operation from your Couchbase database.
There is no structure or definition to the content; any document in a Couchbase database can contain anything and any structure. You can, however, apply a validation routine that checks that the structure of the document supplied to the database. Validation can cover both the fields and their contents.
Also, bear in mind that because there is no strict structure, there is additional flexibility in what, and how, you store the information. Adding a new section to your recipe document that holds data about who supplied the recipe to your database is a case of extending the document structure.
There is also no notion of multiple tables. There is just the database, and documents contained within that database. If you want to support different types of information within the same database then you can add a field to the document. For example, to identify a recipe you might do:
{
"type" : "recipe",
"title" : "Carrot and Coriander Soup"
"servings" : 4,
"subtitle" : "Delicious with wholemeal bread",
...
}
The identification of the record type can be used in other areas of the database system to help you recognize (and select) the data you are loading.
If everything is a document, how do I get a list of records?
In the first section I talked about how with MySQL you could construct a simple SQL statement to get a list of recipes that include carrots. In MySQL this works by searching for values in the ingredients table to find recipe IDs, and then use a join to get the recipe titles from the recipe table. For speed you would ordinarily use an index to improve the response times of the query, to save individually looking at each record.
In Couchbase everything is a document, and there is no built-in method to search the field of a table, since there are no fields and no tables either. Because there is no rigid structure in place (and no way for the database engine to identify the fields in a free-form document), how do we do any operations that normally operate on a list (or table)? Everything from a simple ‘list all recipes’ to ‘find all recipes with an ingredient of carrot’ rely on the use of a list somewhere.
Couchbase supports a construct called a view. Views are similar in principle to the views within MySQL, except that in Couchbase, views are the only way to get lists of documents out of your database, not a method of getting an alternative . A view in fact defines three things:
The structure of the information included in the view. You can think of this as defining the structure of the table, just as you would define a table within MySQL.
The fields or information that can be searched. A view outputs two elements, a key and a value. The keys form the method by which you can search, or more specifically, select, the database content that you want.
An index on the structure and keys. The index is used to improve the searching of the data reported in the view.
Views are defined within a design document, in JavaScript, using a function that accepts a a document. When the view is constructed, every document in the database is supplied to the view, and the view then emits the information that you want to appear in the output. Don’t worry about the JavaScript, the JavaScript is executed on the server, not the client.
So, returning to MySQL for a moment, a query (without a WHERE clause), selects the fields to be returned the query output, and constructs a list of matching rows in the output. So, looking at an SQL statement:
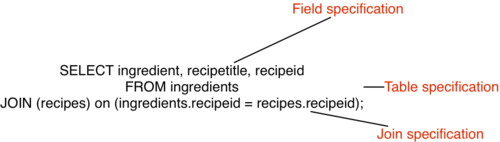
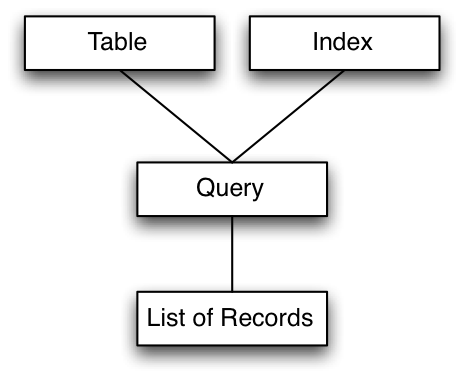
When running a query on MySQL, the MySQL server takes the information in the table or tables, and then constructs the list of records (and corresponding fields) to be returned, like this:
On Couchbase, Views construct a list of records from the individual document information, creating an index as a side effect of that process. The result is a list of all the documents generated by the view.
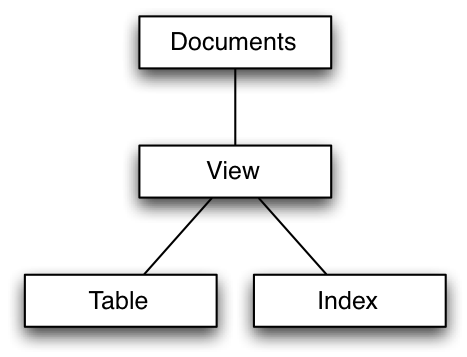
In MySQL, when you execute a query with a WHERE clause, the index (hopefully) is used to help select the records you want to choose:
In Couchbase, the generated view is your table, and when you query the view, Couchbase uses the key values (and the associated index that was generated), with the query values that you specify filtering out the returned information to generate the final list of matching records.
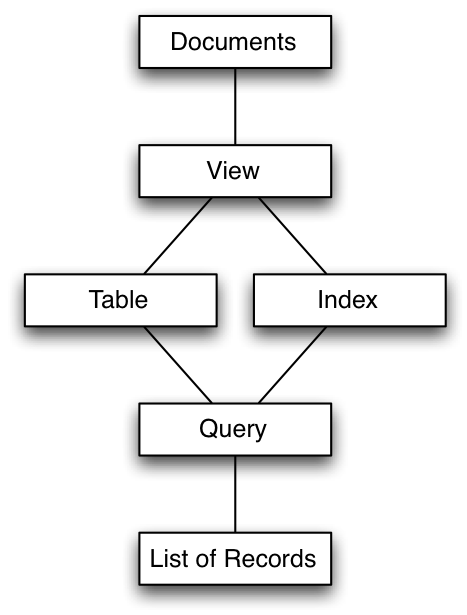
This method of specifying the tables that you want to query enables you to simplify and optimize the way you extract information from the database. But it also means you need to give some more thought to how you want to query the information.
Conclusion
Now you know how MySQL stores and queries information, and how that knowledge that can be translated when you migrate information to Couchbase Server 2.0. In part 2, we’ll start building some queries based on what we’ve learned, and start looking at more advanced queries and the migration process.